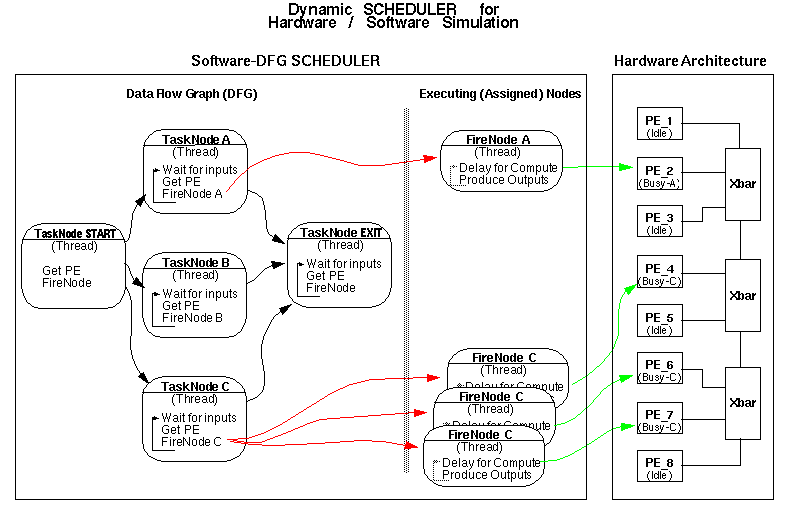
Figure 1 - Dynamic SCHEDULER Model
While the SCHEDULER_2.0 introduces several new capabilities, it still complies to the standard interfaces and Computational Flow-Graph (CFG) paradigm based on Petri-networks. The DFG-GUI is still used to capture and edit DFG graphs.
The SCHEDULER_2.0 now implements a task-node model that is user-definable and is analogous to the device models for the hardware domain. Many of the same capabilities and conventions for describing hardware-devices are now available to describe DFG task-nodes. Some features for describing task-nodes are necessarily different, reflecting the distinct nature of DFG-task-nodes from that of hardware devices.
With this new capability, several new node-types have already been added. For instance: the All-Or-Nothing, and Get-Any-In-Group node-types help to implement new and different mapping/allocation policies.
This document describes the new features. The standard features are covered in the basic scheduler document.
The basic purpose of an AON node is to fire a group of nodes (the AON-node's descendents) if-and-only-if all nodes in the group are ready to-, and can-, execute. If any node in the descendent group cannot execute because a resource is un-available at the time the AON-node completes its task, then the AON will not produce, and none of the descendent nodes will be fired.
Specifically: When an AON node fires, it will produce data on its output arcs only if:
1. Its descendent nodes have not reached their input-arc thresholds and therefore are not ready to fire. Or, 2. Descendent nodes are ready to fire, and resources (PEs) are available for them.In the case of (2) above, the resources are assigned immediately.
If the descendent nodes would be ready to fire once the AON produced, but resources for the descendent nodes are not available (at the production-time), then the AON node will produce no data on its output arcs. In such a case, the firing of the AON node will, in effect, be forgotten, as if it never happened.
Limitations: The output-arcs of an AON node should all have the same produce/threshold/consume ratios. Operation with mixed-ratios is undefined.
The GetAny node-type works differently, in that instead of enforcing a mapping sequence, it will map to any device in its mapping-list that is free. If none are free, then it will map to the first device in its list that becomes free.
Any node having the letters GetAny in its type-name is considered a GetAny type of node.
A new operator has been added to the set of previously available operators (+,-,*,/). You can now use the % percent sign to indicate the modulus operation. Modulus, (x % y), is the integer remainder if x is divided by y.
Note that macros are not data-variables in the normal sense of variables in program code. Although in many respects they are similar, except that the macros are expanded and evaluated in each instance. (Deferred evaluation.)
For example:
macro a = 5 macro b = 2 * a print a, b a = 5, b = 2*a = 10 macro a = 7 print a, b a = 7, b = 2*a = 14This could result in infinite recursion for self-inclusive macros.
A new class called variable has been added that assigns the current evaluated value to the object name. (Immediate evaluation.)
For example:
macro a = 5
variable b = 2 * a
print a, b
a = 5,
b = 10
macro a = 7
print a, b
a = 7,
b = 10
The variable type is especially valuable when using random numbers.
For example, often several values depend on one random quantity.
This would not be possible to express with macros, because each reference
would be a new call to the random generator. Instead, one random number
can be generated and saved as a variable and the same value can be referenced
multiple times.
For example:
Using a variable to store the RANDOM value:
variable message_size = ROUND( 1000 * RANDOM )
macro Bandwidth = 100.0
macro xfer_delay = message_size / Bandwidth
print message_size, xfer_delay
message_size = 375
xfer_delay = 3.75
print message_size, xfer_delay
message_size = 375
xfer_delay = 3.75
But with only macros:
macro message_size = ROUND( 1000 * RANDOM )
macro Bandwidth = 100.0
macro xfer_delay = message_size / Bandwidth
print message_size, xfer_delay
message_size = 375
xfer_delay = 5.21
print message_size, xfer_delay
message_size = 863
xfer_delay = 1.09
(RANDOM was re-evaluated on each reference of the macro.)
4. Creating New Task-Node Type Definitions DFG task nodes are now described in user-editable model-code that is very similar to the way the hardware models are described. The sections below describe the standard node-definitions, from which new variant node-types can be created. Subsequent sections show how to create the custom node-types.
The basic node model contains two parts, which are implemented as threads:
Figure 1 shows the organization of the dynamic SCHEDULER and its interaction with the hardware models. The SCHEDULER is implemented as a single entity that contains many threads. The threads are of the TaskNode and FireNode variety.
Most of the usual language-features are available as they are in hardware models, such as DELAY(), printf, or anything that can be done in ANSI-C.
Additionally, several new functions specific to DFGs are available:
The RECEIVE / SEND functions are NOT available for DFGs, because these are specific to transferring data through hardware ports. Instead, the analogous Block_for and Produce are provided for DFGs.
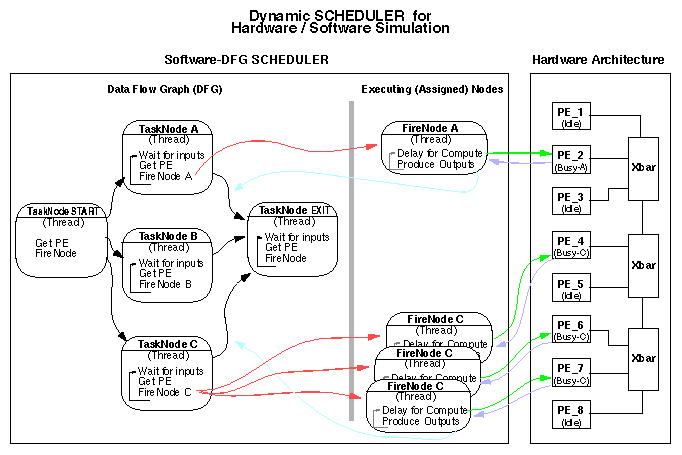
The previous figure showed the feed-forward portion of the control process with colored arrows. Figure 2, below, shows the complete process by adding the feed-back paths.
/*-------------------------------------------------------------*/
/* TaskNode thread waits for node-firing condition, and */
/* dispenses a fire_node thread for each firing. */
/* Specifically: */
/* 1. Wait for sufficient data on my input arcs, and */
/* consume it, */
/* 2. Wait for and/or get resource (PE) to execute on. */
/* 3. Trigger fire_node, while going back to step 1. */
/* */
/* (TaskNode is always running: Except while transitioning */
/* between steps, it is waiting either on step 1 or 2.) */
/*-------------------------------------------------------------*/
DEFINE_THREAD: TaskNode
{
int runflag=1;
struct DFG_NODE *thisnode;
struct fire_mapping *firemapped;
thisnode = (struct DFG_NODE *)THREAD_VAR;
while (runflag)
{
/* Wait until all my input-arcs have sufficient data. */
Block_for( thisnode->input_arcs );
/* Get a resource and pass to fire_node thread. */
if (index(thisnode->type_name,"GetAny")==0)
firemapped = Get_Any_Resource( thisnode );
else
firemapped = Get_Next_Resource( thisnode );
if (index(thisnode->task,"GEN")==0)
TRIGGER_THREAD( fire_gen_node, 0.0, (int)firemapped ); /* GEN-type node. */
else
TRIGGER_THREAD( fire_node, 0.0, (int)firemapped ); /* Normal-type node. */
/* Make sure "START" node fires only once. */
if (thisnode->input_arcs==0) runflag = 0;
}
}
END_DEFINE_THREAD.
/*-------------------------------------------------------------*/
/* Fire_node thread takes care of: */
/* 1. Delaying for the "compute-time", */
/* 2. Producing data to the node's output arcs, */
/* 3. Iterating the firings "iterations" times, */
/* 4. Releasing the resource on completion, */
/* 5. Printing activity to screen for user viewing, and */
/* 6. Saving program instructions for recv, send, compute. */
/*-------------------------------------------------------------*/
DEFINE_THREAD: fire_node
{
/* Set-up local variables. */
int iter;
struct DFG_NODE *thisnode;
struct fire_mapping *firemapped;
firemapped = (struct fire_mapping *)THREAD_VAR;
thisnode = firemapped->task_node;
for (iter=0; iter<thisnode->iterations; iter++)
{ /*iter*/
/* Call any optional user function here. */
/* Print-out notable acitivity and record Time-Line data. */
Report( firemapped, iter );
/* Issue the corresponding Program-Commands. */
Issue_Compute_Command( thisnode, firemapped->pe_assignment );
/* Delay for the compute duration. */
/* This Delay is not used in the dynamic version, */
/* in lieu of PE-handshake in Issue_Compute_Command. */
/* DELAY( thisnode->compute_time ); */
/* Produce data onto this node's output arcs. */
Produce( thisnode, firemapped->pe_assignment );
if (verbose>0) printf(" Producing for '%s'\n", thisnode->task );
} /*iter*/
/* Release the Processor Resource. */
free_pe( firemapped->pe_assignment );
free( firemapped );
}
END_DEFINE_THREAD.
How do you make your new Task-Node types known to the GUI? So that user's can quickly know the types of new DFG node types you provide, the correct spelling of their type-names, and be able to quickly select them, you can add stub-definitions in the following form to a DFG file.
DEFINE_NODE_TYPE: MyNewCustomNode_1 PORT_LIST( out ); DEFAULT_ATTRIBUTES( firing_rate = 1.0 ); END_DEFINE_NODE_TYPE.Notice that you can provide the default attributes of your custom node types this way too. The format is similar to the definition of a hardware device, except for the keyword "NODE".
This section describes how such custom nodes are created
You can define a custom task-node by modifying the TaskNode or FireNode threads of the standard SCHEDULER model. Place if-branches, around lines of your custom code, that are sensitive to the type-name of your custom node type.
For example:
if ( strcmp( thisnode->type_name, "YourCustomNodeName" )==0 )
{
/*Your custom code. */
}
Where YourCustomNodeName is your custom node-type name.
Then set the type-names of any of your DFG task-nodes to the type-names that you have provided for. You can do this conveniently using the GUI.
Next, build and run the simulation. You may see warning messages about any syntactical errors in your custom code during compilation, or logical errors during the simulation. You would then iteratively fix any such errors.
This forms a kind of branch in the flow-graph, because only one of two descendent branches will receive the stimulus-token. It changes the outcome of the successive execution stages of the graph.
We will call this new node-type: RandomBranch
We would set the type, of any nodes in our DFG that we wish to be of
this type, to this name in the DFG-GUI.
To define this custom node-type, a few lines of code within the SCHEDULER's fire_node thread are modified. Specifically, the line:
/* Produce data onto this node's output arcs. */ Produce( thisnode, firemapped->pe_assignment, comp_no );... is modified to:
if (strcmp(thisnode->type_name,"RandomBranch")==0)
{
double ftmp;
char expression[] = "TRUNC( 1.9999 * RANDOM)";
char pname[3];
eval( expression, &ftmp );
sprintf(pname,"p%d", (int)ftmp );
Produce_on_port( thisnode, firemapped->pe_assignment, comp_no, pname );
}
else
/* For regular nodes: */
/* Produce data onto this node's output arcs. */
Produce( thisnode, firemapped->pe_assignment, comp_no );
First the if-statement must branch regular nodes around
the custom code. So we see the test on the node-type name and the standard
Produce() call after the else (at the bottom).
The "core" of the custom code block consists of a few temporary variable declarations, and the use of the eval call to evaluate the random expression. (This could have been done by calling the C-subroutine random directly, but was done this way for illustrative purposes. It shows how DFG-macros can be evaluated too.) The result of the evaluation should be an integer 0 or 1. This is value passed into the standard sprintf function to make the port-name: p0 or p1 accordingly.
The randomly selected port-name is then passed to the Produce_on_port() function, which causes data to be produced only on the named port.
Many other custom nodes can be developed by writing custom code that calls the built-in routines at appropriate times.
The Block_for routine is used to wait for sufficient data to accumulate on all the input arcs to a task-node. Upon satisfaction of all threshold amounts, it decrements the input arcs by the consume-amount and returns.
The Block_for_port routine is like the Block_for routine, except that it operates on the single input arc specified by the port-name. This routine is intended for forming graph-nodes that operate on a variant rule-set as compared to the standard computational-flow-graph paradigm.
The Get_Next_Resource routine checks to see if a PE resource is available to execute the task. It consults the mapping-list of the task node to see what PE, or group of PEs, the task is mapped to. If a PE is not available, this routine will sleep until the next appropriate PE is available. When the PE is available, it is assigned to this task, and the routine returns.
The Get_Any_Resource routine is like the Get_Next_Resource, except that it will allocate any available PE from the group specified in the task's mapping-list, irregardless of sequence. "First-available".
The Get_Descendant_Resources routine is a special variant of the Get_Next_Resource function for implementing AON nodes. It is called from an AON task-node when it completes its computation delay, just prior to producing data on its output arcs. This routine checks to see that all the descendent task nodes can be immediately assigned to available PEs. If so, then it assigns them and returns with +1, indicating successful descendant allocation and indicating that data should be produced on the output arcs. If not, then it returns with 0, indicating that no output should be produced on the output arcs of this node. (The descendant nodes are the task-nodes attached to the other-ends of the output arcs of the current task-node.)
The Issue_Xfer_Commands routine causes the sendmessg / recvmessg commands to be issued to the respective PEs from-which, and to-which, the transfers must originate, and be sent, respectively on all the input-arcs for a firing of the task-node.
The Issue_Xfer_Command_on_port routine is like the Issue_Xfer_Commands routine, except that it issues transfer commands for only the input-arc specified the port-name of the task-node. This routine is intended for forming graph-nodes that operate on a variant rule-set as compared to the standard computational-flow-graph paradigm.
The Issue_Compute_Command routine causes the compute-command to be issued to the assigned PE for the task-node at-hand.
The pull_data routine is used for passing actual data values across flow-graph arcs. This routine removes data from an input arc, placing it in a local variable. It is normally called after returning from a Block_for to ensure there are sufficient for data on the input-arcs. Additional discussion is provided here.
The push_data routine is used for passing actual data values across flow-graph arcs. This routine places data from a local variable onto the arc attached to the specified output port of a task-node. It is normally called after issuing the compute operation, but just prior to incrementing the data amounts (producing) on the output arcs, so that descendant task-nodes can pull the data from the arcs when they fire. Additional discussion is provided here.
The push_data_outall routine is like the push_data function, but it places the data item on all of a node's output arcs, instead of a specific arc. It is used for passing actual data values across flow-graph arcs. This function does not require a port-name. Additional discussion is provided here.
The free_pe routine de-allocates the PE assigned to the current task-node after completing the computation. The PE is then ready for re-assignment.
The Produce routine increments the data-amounts on all the output arcs of the task-node. The increment amounts are as-specified by the arc's produce-amount. If any descendent tasks that were waiting for sufficient data are now ready-to-run, they are returned from their Block_for calls.
The Produce_on_port routine is like the Produce routine except that it increments the current data-amount of only the arc attached to the specified port of the task-node. This routine is intended for forming graph-nodes that operate on a variant rule-set as compared to the standard computational-flow-graph paradigm. In particular, this function is useful for creating branch-node type of task-nodes. It enables only one (or a subset) of several output arcs to receive data.
Below is the formal definition of each of the functions.
void Block_for( struct ARC *inlst_arc ) void Block_for_port( struct ARC *inlst_arc, char *pname ) int Get_Next_Resource( struct DFG_NODE *thisnode ) int Get_Any_Resource( struct DFG_NODE *thisnode ) int Get_Descendant_Resources( struct DFG_NODE *thisnode ) void Issue_Xfer_Commands( struct DFG_NODE *tasknode, int map_pe, int comp_no ) void Issue_Xfer_Command_on_port( struct DFG_NODE *tasknode, int map_pe, int comp_no, char *pname ) void Issue_Compute_Command( struct DFG_NODE *tasknode, int map_pe, int comp_no ) void *pull_data( struct DFG_NODE *nodeptr, char *portname ) void push_data( struct DFG_NODE *nodeptr, char *portname, void *data ) void push_data_outall( struct DFG_NODE *nodeptr, void *data ) void add_macro( char *macro_name, char *macro_stringvalue ) int eval( char *macro_string, double *return_data ) void free_pe( int pe_id ) void Produce( struct DFG_NODE *tasknode, int map_pe, int comp_no ) void Produce_on_port( struct DFG_NODE *tasknode, int map_pe, int comp_no, char *pname )
The functions are described in detail below.
Each call to pull_data pulls the next data item from the given arc-queue. It returns with a pointer to that item. Many data-items may be pulled from the queue during a given firing. If pull_data is called while the port-queue is empty, the returned data-pointer will be zero. It is good practice to test for the zero-pointer condition.
Each call to push_data pushes another data item onto the given arc-queue. Many data-items may be pushed onto a queue during a given firing. All items are queued, so that if the descendent node does not execute while the producer fires several times, no data will be lost. The descendent will pull the data in the sequence it was pushed on the queue.
Each call to push_data_outall pushes another data item onto each output-arc-queue. Many data-items may be pushed onto the queues during a given firing. All items are queued, so that if descendent nodes do not execute while the producer fires several times, no data will be lost. The descendents will pull the data in the sequence it was pushed on the queue.
Eval returns a value indicating the type of data that input string expression evaluated to.
Where: -1 = error, 0 = alpha-numeric string returned in result parameter, 1 = integer, and, 2 = double-float.Numerically resolved results (cases 1 and 2) are returned in parameter "value". They are always returned as type double. Integers should be deconverted. (ie. ival = (int)dval; ).
The formal defintion of the eval function is:
int eval( char *line, double *result )
The formal defintion of the add_macro function is:
void add_macro( char *macro, char *value )
$CSIM_ROOT/model_libs/core_models/dynam_sched.dirIn file:
dynamic_sched.simYou can include this file in your model if you are not using any custom DFG-nodes. (Otherwise copy it, and modify the copy.) Instantiate one instance of the scheduler in a box that is not connected to anything (similar to the monitor.sim).
Several complete examples are contained the examples directories below the dynam_sched.dir directory.
Usage:
To use the Dynamic Scheduler, include:
monitor.sim (as in any core_models simulation),
and
dynamic_sched.sim.
The order you include them should not matter.
The dynamic_sched.sim file will include other files, such as
dynsched.h, SchedRoutines.c, parse.c, and parse3.c.
(You may need to copy these to your local directory.)
