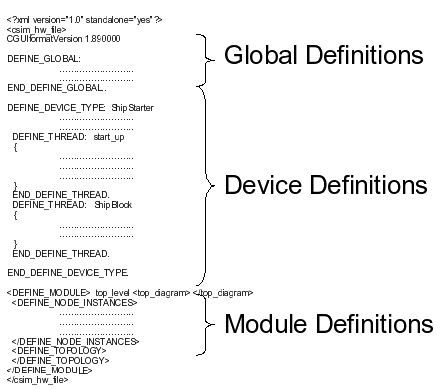
Figure 1 - Basic layout of CSIM models.
Table of Contents
1. CSIM
1.0 Overview
1.1. CSIM Code Layout
1.2. CSIM Setup
1.3. Advanced CSIM Topics
1.3.1. Named Synchrons
1.3.2. TRIGGER_THREAD versus CALL_THREAD
1.3.3. Iterator
1.3.4. Attributes
1.3.5. Wormhole
1.3.6. Compiling CSIM code
1.4. CSIM Sample Code Layout
1.5. Distribution & Visualization
1.5.1. Wormhole
1.5.2. 3D viewer
This material covers the first steps in implementing general C++ software models for use with the CSIM runtime engine. The basic features of CSIM relative to generic or legacy model-integration are reviewed, including message passing, event scheduling, and compilation.
The device definition section contains all the different model definitions. Therefore, any object that has the potential of running on separate entities, system components, or places, should be defined as different devices. By defining the devices in this manner, the only method of communicating between elements is messaging, as in an acutual system. Defining this section typically requires the use of textual input; however, the CSIM GUI can be used to generate the skeleton software.
The last section of CSIM code contains the module definition. This section defines the number of model instances that will be instantiated at runtime. It also contains the instance attributes described in Section. This section can be completely created by the CSIM GUI.
The command
source csim_path/setup
... will properly set the configuration parameters for use of CSIM. Where csim_path is the base folder of the CSIM software installation. This sets the location where CSIM is located on your system , sice CSIM can be installed under various locations. Like other software, typically users operate with data files in their own working directories, while the tools and libraries are referenced from the installed package location.
Sourcing the setup file will establish the CSIM license as well as many aliases. Some commonly used aliases that this setup file generates are seen in Table 1.
| Alias | Function |
| gui | Opens the CSIM graphical user interface |
| csim | Invokes the CSIM preprocessor on a specified .sim file |
| iterator | Starts the CSIM iterator using a specifed .control file |
CSIM's Iterator-GUI creates a control file to define the iteration parameters. The default file is called iteration.control and is placed in the same directory as the CSIM file. This file defines the attribute values, ranges, the simulation executable, and any hosts for distributed processing. The iterator is launched by the command
iterator myScript.control
... where myScript.control is the name of the control file defining
behavior of the desired iteration. If myScript.control is omitted, the
iterator will default to access a file called interation.control in the
user's present working directory. More information and examples can be
found at:
Iterator
One advantage of attributes is that a Monte Carlo run may sweep over a certain attribute. However, if a simulation contains more than one instance of the device, the Monte Carlo functionality will sweep the same attribute for both instances. An additional attribute can be added to a single instance to sweep that instance. By setting the desired attribute to be swept equal to this new attribute, only the single instance will change. For example, to sweep over the vehicle number of a device the following attributes could be used.
Entity1:
vehicNum = enity1_vehicNum
enity1_vehicNum = 0
totFuel = 5
Entity2:
vehicNum = 10
totFuel = 5
The Iterator could then be used to sweep the values of the attribute enity1_vehicNum, instead of
vehicNum. If vehicNum were swept directly, it would affect both
entities. By sweeping the enity1_vehicNum attribute, the
vehicNum attribute of only the first instance will be affected.
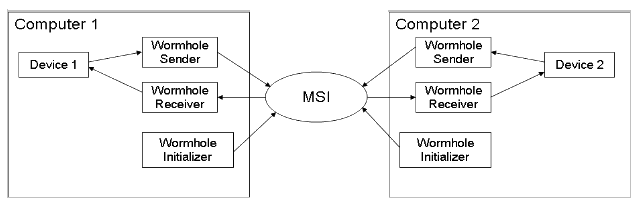
The MSI-server resides locally on one machine, which creates a small inherent lag as all messages travel through the same computer. However, the computer that runs MSI can be a dedicated server to reduce this effect. Figure 2 illustrates that the wormhole consists of 3 parts, an initializer, sender, and receiver. To connect to the MSI server, an MSI client, or wormhole intializer, connects upon the CSIM startup. Each message is then received or sent via a wormhole receiver or sender to the appropriate device.
The final effect of this structure is that each message type will need a pack and unpack method to store its data to a string. This is not overly complicated but requires additional work per message type. Therefore, an abstract data type is the best method of passing messages, as per the example.
One important consideration when constructing distributed simulations is that CSIM will close when there are not any processes on the queue. Therefore, if one of the distributed functions has down time, a counter, spinner, or timer is needed to add spurious tasks onto the scheduling queue. Without this simple function, the executable will close while awaiting messages from another process.
csim -arg my_file.sim... where arg is one of many different CSIM compilable codes that are listed in Table 2. There is a more extensive list of different capabilities at:
| Argument | Description |
| -nocomp | Stops the csim preprocessor from automatically compiling out.c. This is needed for complex models to link the correct libraries. |
| -nongraphical | Prohibits the csim preprocessor from adding in graphical elements to the simulation, allowing the simulation to be run from the command line. |
| -trace | Adding this argument will make debugging lines appear during runtime. The debugging lines are always surrounding different CSIM calls, like TRIGGER_THREAD. |
| -compile_all | When defining a model, all the devices do not have to be used in the module definition. Using this argument will compile them anyway, even though they should not be used during run-time. |
After generating C code from the CSIM preprocessor, the code is typically compiled automatically. Originally, CSIM was meant only for C syntax. Therefore, it uses the gcc compiler by default, aliased under CSIM_C_COMPILER and CSIM_CL_COMPILER. The CSIM_CL_COMPILER is used for non-graphical compiles, while graphical compiles use the CSIM_C_COMPILER. Without using the appropriate compile method, the CSIM out.c will not compile. In addition, any necessary external libraries need to be linked during the compile. You can add additional options to the CSIM_C_COMPILER or CSIM_CL_COMPILER environment variables by redefining them. ALternatively, you can use the CSIM option, -nocomp, during preprocessing. The code will not automatically be compiled, allowing you give your own compile comamnd separately. For example, you might switch to compile with a C++ compiler by changing the alias, all the functionality of CSIM is available in C++.
Appendix A shows the code which consists of the three main sections illustrated in the Section. First, the global section contains messaging and event scheduling which are functions required by many modeling projects. The scheduling function triggers the thread of the device that it is pointed to. Each device must have their event thread prototyped within the global section for the program to work. Since there can be multiple instances of the same thread, a device must only call events for itself; otherwise, messaging should be used. Due to CSIM naming convention, the prototype follows the format:
void DeviceName_ThreadName (void* arg);... where DeviceName is the name of the device where the prototyped thread resides, and ThreadName is the name of the thread. Finally, each thread can take a void* as an argument (the name arg is generalized).
The event scheduler routine, scheduleEvent, constructs an event package based upon the input data and schedules the event on the given device. The scheduled device should be the same device that schedules the event. It uses TRIGGER_THREAD to call the prototyped thread at the given time delay.
Messaging is more complicated than the events because there are two methods of sending a message, asynchronously and synchronously. An asynchronous message is a fire-and-forget type of message, meaning that the device that schedules the message has no immediate concern about it being processed and continues its own processing. The second message type, synchronous, is the opposite. It needs the other device to finish its processing before it can proceed with its task. A synchronous message waits for a return from the message before finishing its processing. For both message types, the messaging function will call a synchron based upon the destination of the message; a naming convention is discussed later. With the first message type, asynchronous, it schedules a resume of the given message. However, for the second message type, synchronous, it packages an extra synchron with the message and waits on that synchron until the message receiver resumes the extra synchron.
The naming convention for this example program consists of the device name, vehicle number, and, where applicable, the instance number. For a vehicle, the name would be vehicIn plus the number of the vehicle. So, for vehicle number 1 the vehicle synchron name would be:
vehicIn001A projectile is an example of a device that could possibly have more than one instance per vehicle. This would result in a name for the second projectile of the first vehicle being:
projectileIn001002This naming convention gives the program the ability to have up to 1000 vehicles and 1000 instances of an object per vehicle without any possibility of naming conflictions.
The second main section of code contains the different device definitions, which basically follow the same rubric. The current layout of the devices includes four threads. The first thread is simply CSIM startup; it runs all the backbones of the CSIM environment including initializing all the lines of communication. The second thread is called directly by the CSIM startup and contains the actual model initialization. For this example, the model startup is a simple new statement, but more detailed models can use more sophisticated initialization. The other two threads are event handling and message handling threads. They take the messages and events and call the specific handler for the model.
The final section of code, module definitions, defines how many devices the program will have at runtime. The current configuration contains 2 vehicles with 2 projectiles per vehicle; however, this is very simple to change for different test cases.
The second main issue with the MSI wormhole is time locking. To assure proper causality, MSI prevents one simulator from advancing time ahead of the other(s). This may reduce the speedup potentially available. MSI contains a built-in time-slack parameter, epsilon, which can relax the timing lock and allow greater speed-up. For example, it can be set to allow one simulator to advance a fraction of a second ahead of another, and enable greater parallel computations. However, setting epsilon too large could lead to serious synchronization issues in some models.
The 3D viewer can display various 3D objects which can be described in the simple WinFrame XML format.